


GRAPHICS PROCESSING UNIT
CS/ECE 6810: Computer Architecture
Mahdi Nazm Bojnordi
Assistant Professor
School of Computing
University of Utah












Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Community
Ask the community for help and clear up your study doubts
Discover the best universities in your country according to Docsity users
Free resources
Download our free guides on studying techniques, anxiety management strategies, and thesis advice from Docsity tutors
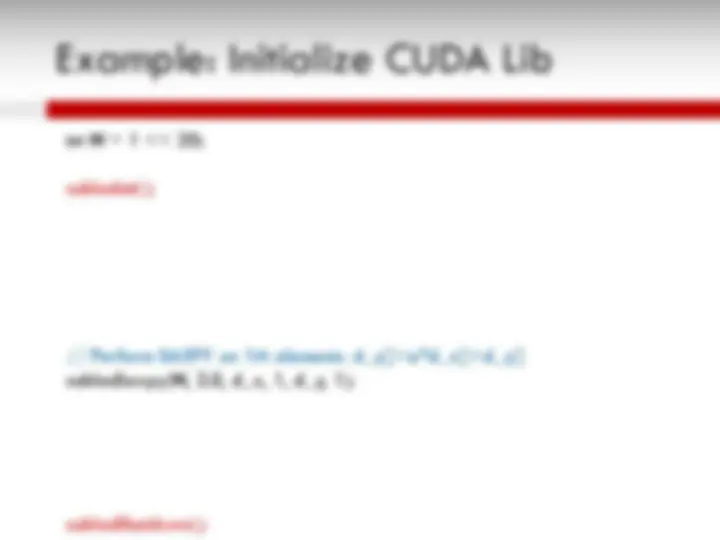
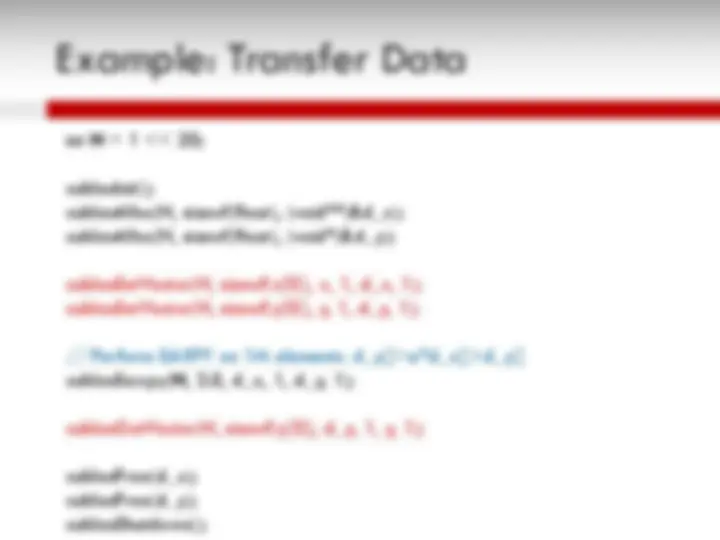
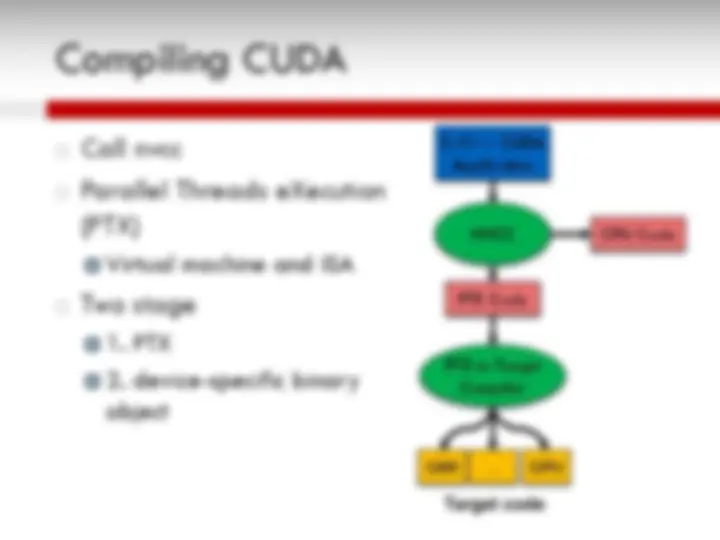
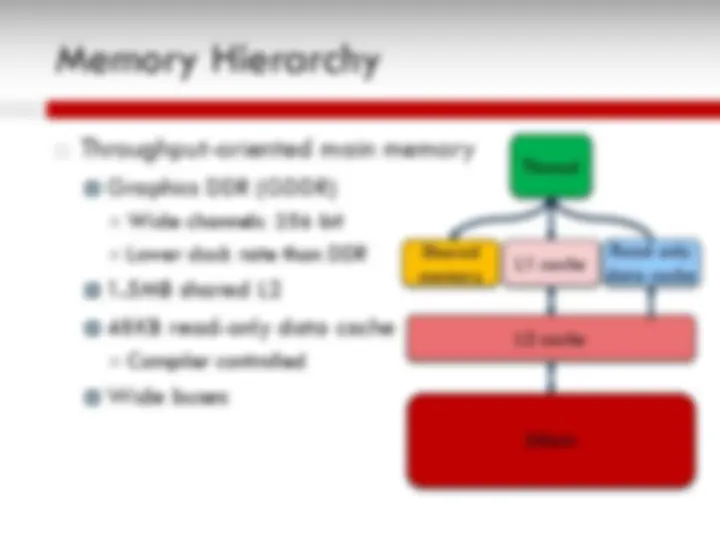
An overview of the Graphics Processing Unit (GPU) architecture, its initial development as graphics accelerators, and its evolution as a dense compute engine for non-graphics workloads. It also explains the CUDA programming model for scientific applications and the SAXPY computation example. The GPU architecture is based on SIMT (single instruction, multiple threads) model with many SIMT cores, thread blocks, warps, and in-order pipelines. The CUDA programming model includes steps for substituting library calls, managing data locality, transferring data between CPU and GPU, and allocating memory.
What you will learn
Typology: Summaries
1 / 25

This page cannot be seen from the preview
Don't miss anything!
Graphics Processing Unit (GPU) host interface memory interface Vertex Processing Triangle Setup Pixel Processing
host interface memory interface Vertex Processing Triangle Setup Pixel Processing
¤ one of the densest compute engines available now
¤ general-purpose GPUs (GPGPUs)
¤ CUDA from NVidia and OpenCL from an industry consortium
¤ a regular host CPU ¤ a GPU that handles CUDA (may be on the same CPU chip)
¤ GPU has many SIMT cores
Source: NVIDIA